Research Summary
My research lies in machine learning and data mining and spans the theory and algorithms of large-scale graph mining, statistical machine learning, and their applications in social and information networks. Recently, I have been working on the design of statistically efficient and scalable algorithms and frameworks for modeling and mining massive dynamic networks.
Previously, I have worked on the problem of timeseries prediction using machine learning models, and proposed various feature learning methods that can be used in conjunction with neural network models for highly-accurate predictions. We Tested our models on the large-scale M3 and NN3 timeseries benchmark datasets. For an in-depth study, please check our journal paper. I have also participated in the NN3 timeseries prediction competition, and my predictions were ranked the 5th (with less than 1% error increase over the best methods, including the statistical benchmark package ForeacstPro).
During my research visit at Adobe labs, I worked on statistical analysis of daily deals using data from Yelp, and Grroupon. This work has been recognized by popular press such as the famous MIT Technology Review Magazine.
Research Interests
- Statistical Machine Learning
- Large-scale Graph Mining
- Timeseries Prediction
- Big Data and Streams
- Social Network/Media Analysis
- Interactive Machine Learning and Analytics
Research Projects
-
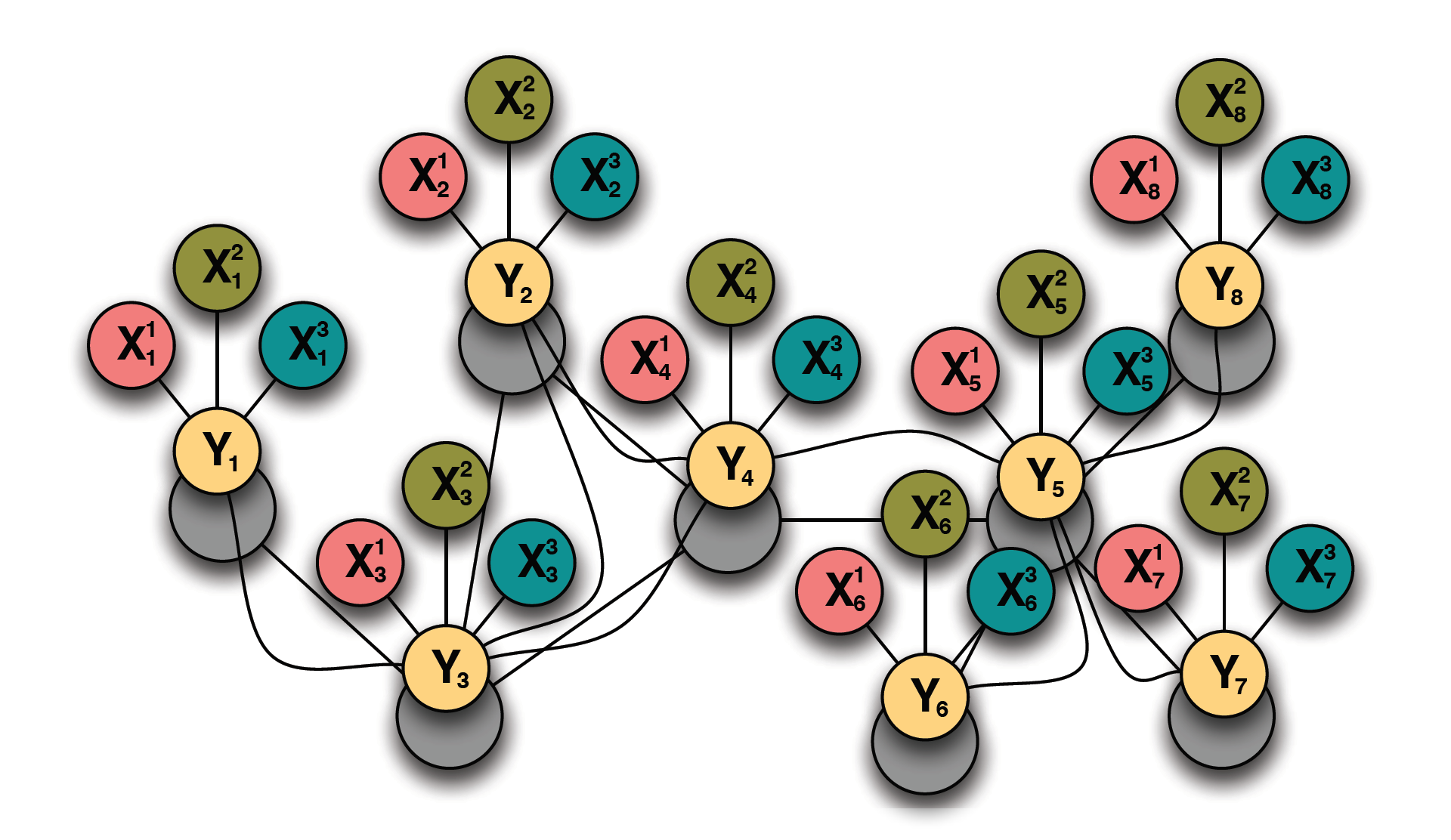
Graphs provide a natural representation of real-world networks e.g. world-wide web, biological networks, social networks, and information networks. Many of theese networks are characterized by the presence of both uncertainty and complex relational structure. Statistical relational learning combines the power of uncertainty and complex relational structure to model complex networked systems. This project focuses on a number of statistical relational learning such as collective classification,link prediction,link-based clustering,social network modeling, network alignment, entity resolution, among others. The main goal of this work is to construct robust statistical models and learn relational feature representations that capture the underlying sstructure and uncertainty in complex networked systems.
-
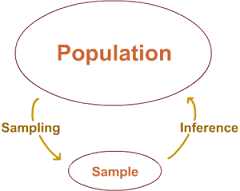
Big data, and in particular graphs and social media data that represent human behavior and interactions, is becoming important for business decisions, cyber-security, and detecting product trends. Recently, it has been noted that big data may not imply better analytics or predictions, especially if it is collected wrong or sampling bias is ignored. Statistical sampling and estimation has been noted as one of the most important considerations when working with big data.
One of the key stumbling blocks for enabling large-scale network analysis and modeling is the limitation in computational resources. Despite the recent advances in distributed and parallel processing frameworks for graph analytics, and the appearance of infinite resources on the cloud, running brute-force graph analytics is either too costly, too slow, or too inefficient in many practical situations. On the other hand, finding an approximate answer via statitical sampling and unbiased estimation is usually sufficient and fast for many types of analysis tasks.
In this project, we focus on efficient (stream-based) sampling and estimation for mining and modeling massive networks. The main contributions of this work are: (a) a unified framework for sampling and estimation of massive networks, (b) theoretical analysis of the statistical bias of various sampling algorithms, (c) developing novel memory efficient (stream-based) sampling algorithms, and (d) efficient unbiased estimation of frequent subgraph patterns (e.g., cliques, hubs, etc).
-
Roles represent node-level connectivity patterns such as star-center, star-edge nodes, near-cliques or nodes that act as bridges to different regions of the graph. Intuitively, two nodes belong to the same role if they are structurally similar. Roles have been mainly of interest to sociologists, but more recently, roles have become increasingly useful in other domains. Traditionally, the notion of roles were defined based on graph equivalences such as structural, regular, and stochastic equivalences which are limiting and harder to compute.
The main contribution of this work is the design of a flexible parallel framework for discovering roles using the notion of similarity on a feature-based representation (in contrast to the graph representation). The framework consists of two fundamental components: (a) role feature construction to transform the graph into a feature representation and (b) role assignment using the learned feature representation from the first step. The framework views role discovery as an approach to cluster the nodes of the graph into groups of similar nodes — such that the similarity is measured using a learned set of features extracted from the node structural properties (e.g., degree), attributes (e.g., age, gender), and aggregate relational properties (e.g., average degree among neighbors).
-
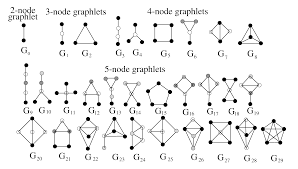
From social science to biology, graphlets have found numerous applications and were used as the building blocks of network analysis. In social science, graphlet analysis (typically known as k-subgraph census) is widely adopted in sociometric studies. Much of the work in this vein focused on analyzing triadic tendencies as important structural features of social networks (e.g., transitivity or triadic closure) as well as analyzing triadic configurations as the basis for various social network theories (e.g., social balance, strength of weak ties, stability of ties, or trust). In biology, graphlets were widely used for protein function prediction, network alignment, and phylogeny to name a few. More recently, there has been an increased interest in exploring the role of graphlet analysis in computer networking (e.g., for web spam detection, analysis of peer-to-peer protocols and Internet AS graphs), chemoinformatics, image segmentation, among others.
While graphlet counting and discovery have witnessed a tremendous success and impact in a variety of domains from social science to biology, there has yet to be a fast and efficient approach for computing the frequencies of these patterns. The main contribution of this work is a fast, efficient, and parallel framework and a family of algorithms for counting graphlets of size k-nodes that take only a fraction of the time to compute when compared with the current methods used. The proposed graphlet counting algorithm leverages a number of theoretical combinatorial arguments for different graphlets. For each edge, we count a few graphlets, and with these counts along with the combinatorial arguments, we obtain the exact counts of others in constant time. Furthermore, a number of important machine learning tasks rely on this approach, including graph anomaly detection, as well as using graphlets as features for improving community detection, role discovery, graph classification, and relational learning.
-
Machine learning models have established themselves in the last decade as serious contenders to classical statistical models in the area of timeseries prediction and analysis. This work studies the interplay between feature representtaion, preprocessing methods, model selection, and data on the accuracy of timeseries prediction. The results show how neural networks and gaussian processes outperform classical linear models for timeseries prediction.
-
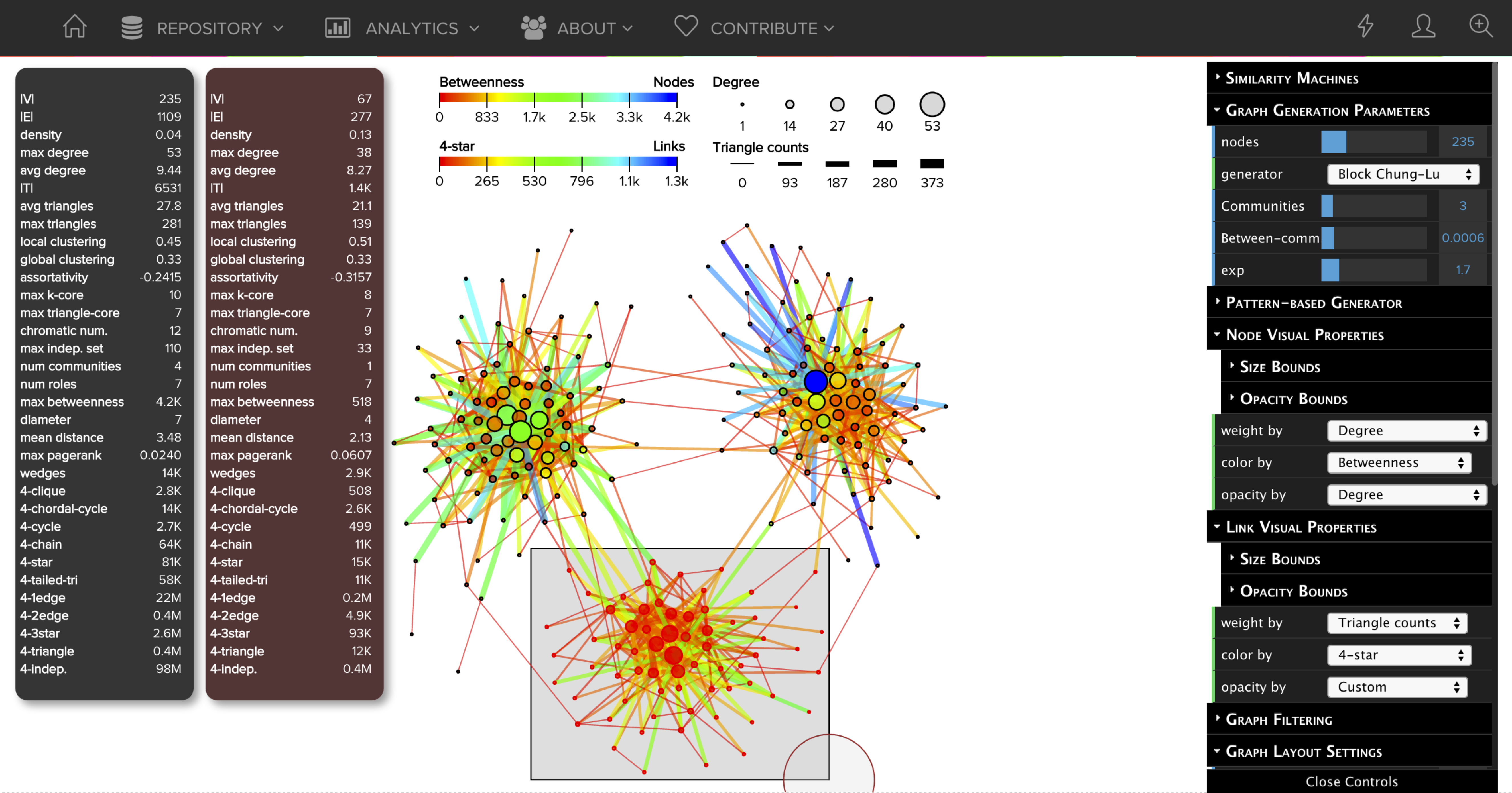
This project develops the foundation of a web-based graph visual analytics platform called GraphVis that combines interactive visualizations with analytic techniques to reveal important patterns and insights for sense making, reasoning, and decision-making. The platform is designed with simplicity in mind and allows users to visualize and explore networks in seconds with a simple drag-and-drop of a graph file into the web browser. GraphVis is fast and flexible, web-based, requires no installation, while supporting a wide range of graph formats as well as state-of-the-art visualization and analytic techniques. In particular, the multi-level network analysis engine of GraphVis gives rise to a variety of new possibilities for exploring, analyzing, and understanding complex networks interactively in real-time. Finally, we also highlight other key aspects including filtering, querying, ranking, manipulating, exporting, partitioning (community/role discovery), as well as tools for dynamic network analysis and visualization, interactive graph generators (including two new block model approaches), and a variety of multi-level network analysis and statistical techniques.